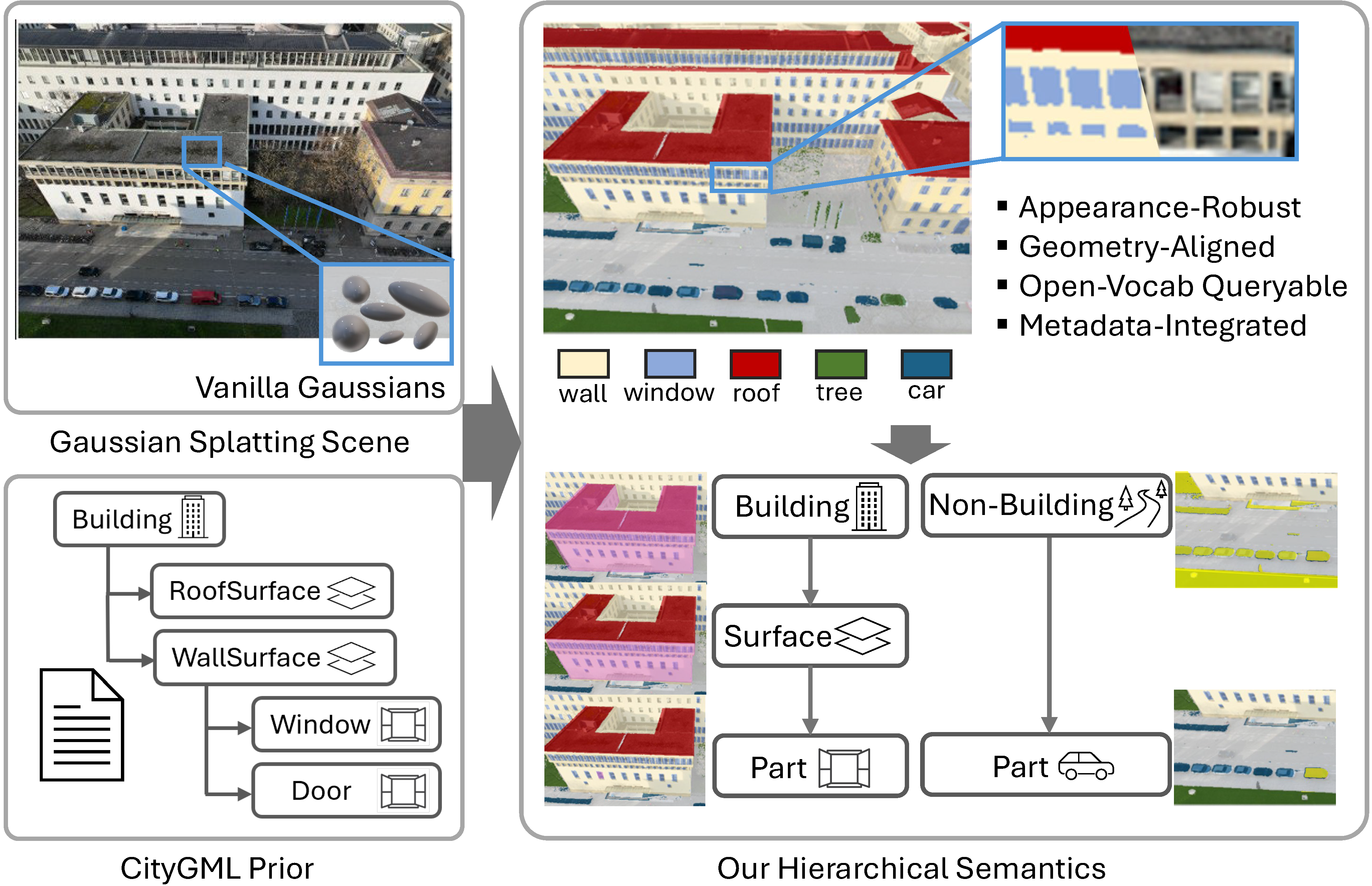
Recent semantic 3D Gaussian Splatting (3DGS) methods primarily rely on 2D foundation models, often yielding ambiguous boundaries and limited support for structured urban semantics. While city models such as CityGML encode hierarchically organized semantics together with building geometry, these labels cannot be directly mapped to Gaussian primitives.
We present GS4City, a hierarchical semantic Gaussian Splatting method that incorporates city-model priors for urban scene understanding. GS4City derives reliable image-aligned masks from Level of Detail (LoD) 3 CityGML models via two-pass raycasting, explicitly using parent-child relations to validate and recover fine-grained facade elements. It then fuses these geometry-grounded masks with foundation-model predictions to establish scene-consistent instance correspondences, and learns a compact identity encoding for each Gaussian under joint 2D identity supervision and 3D spatial regularization.
Experiments on the TUM2TWIN and Gold Coast datasets show that GS4City effectively incorporates structured building semantics into Gaussian scene representations, outperforming existing 2D-driven semantic 3DGS baselines, including LangSplat and Gaga, by up to 15.8 IoU points in coarse building segmentation and 14.2 mIoU points in fine-grained semantic segmentation. By bridging structured city models and photorealistic Gaussian scene representations, GS4City enables semantically queryable and structure-aware urban reconstruction.
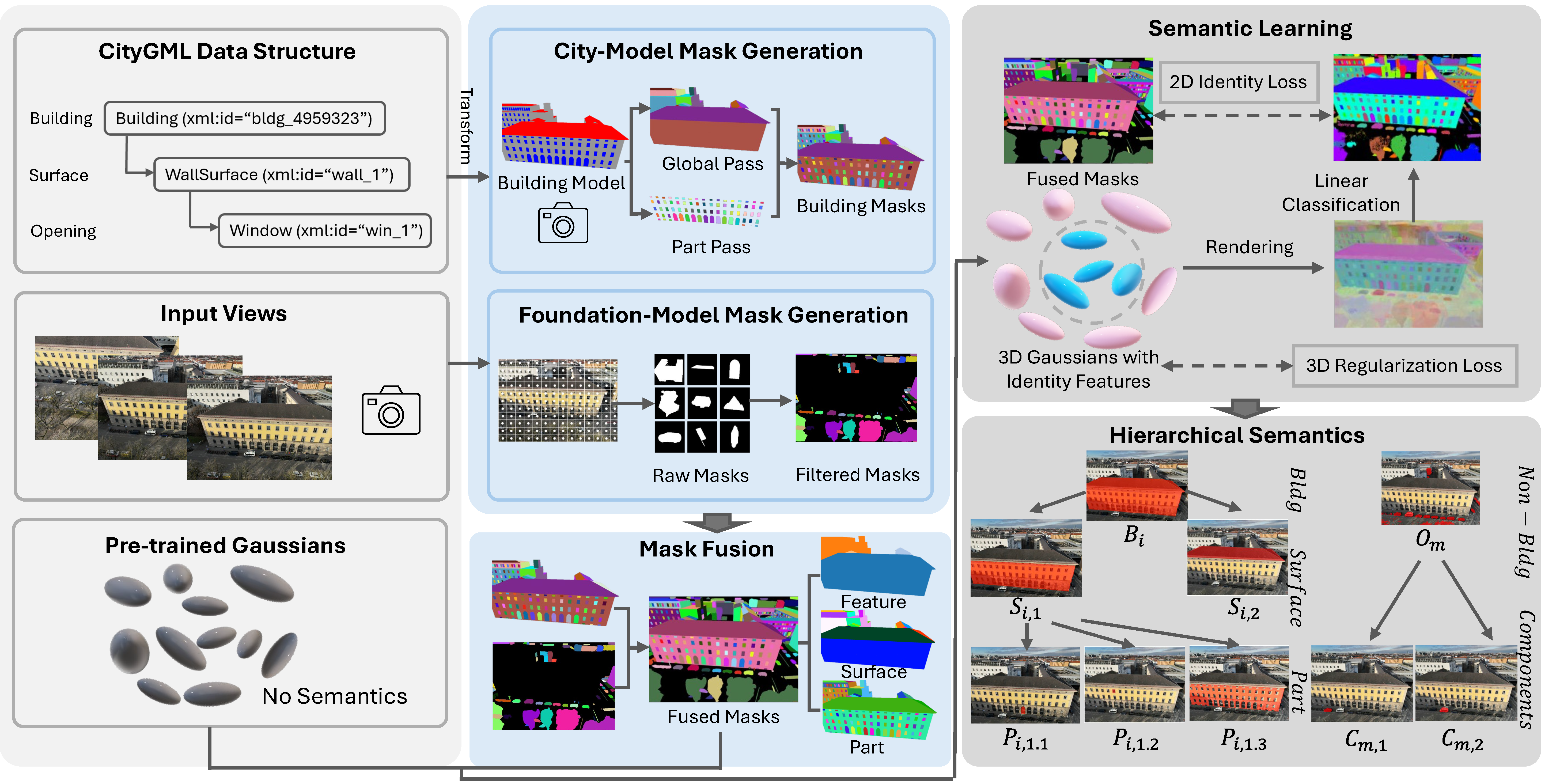
Starting from an aligned LoD3 city model, calibrated images, and a pre-trained 3DGS scene, GS4City proceeds in three stages. First, Two-Pass Raycasting projects the city model into each image view to derive hierarchical, geometry-grounded masks, explicitly exploiting parent-child relations to validate and recover fine-grained facade elements such as windows and doors. Second, Mask Fusion and Instance Linking combines these city-model masks with foundation-model predictions to filter noisy detections and establish scene-consistent correspondences between building entities, image masks, and Gaussian primitives across all views. Finally, Gaussian Identity Encoding lifts the fused correspondences into a compact per-Gaussian feature field under joint 2D identity supervision and 3D spatial regularization, enabling multi-level building parsing, open-vocabulary semantic querying, and interactive urban-scene visualization within a unified 3DGS representation.
GS4City is evaluated on the TUM2TWIN and Gold Coast LoD3 datasets. Select a scene below, then drag the sliders to compare segmentation results against LangSplat and Gaga.

RGB





Qualitative results on representative scenes from TUM2TWIN and Gold Coast at both coarse and fine-grained semantic levels. The first column shows reference RGB views with ground truth derived from labeled point clouds. The remaining columns show predictions of LangSplat, Gaga, and GS4City (ours). GS4City achieves more complete Building / Non-Building separation at the coarse level and more accurate segmentation of challenging facade elements — such as windows and roofs — while avoiding incorrect assignments in non-building regions such as water surfaces.
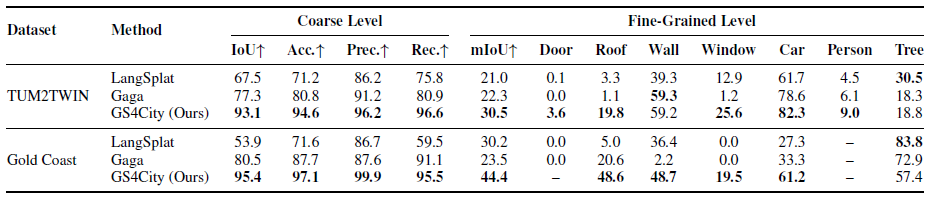
Quantitative comparison at the coarse and fine-grained semantic levels. Coarse-level metrics evaluate Building / Non-Building grouping; the fine-grained part reports overall mIoU together with per-class IoU. GS4City outperforms LangSplat and Gaga by up to +15.8 IoU at the coarse level and +14.2 mIoU at the fine-grained level. All values are in %.
We demonstrate the GS4City interactive viewer for semantic urban scene exploration. The viewer supports three rendering modes (RGB, segmentation, and overlay), click-to-select with CityGML metadata retrieval, multi-level semantic selection across the parent-child hierarchy, and open-vocabulary semantic querying.
@inproceedings{zhang2026gs4city,
author = {Zhang, Qilin and Zhu, Jinyu and Wysocki, Olaf and Busam, Benjamin and Jutzi, Boris},
title = {{GS4City}: Hierarchical Semantic {Gaussian} Splatting via City-Model Priors},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)},
year = {2026},
}